Final dataARC Workshop
Overview
The dataARC Team, led by Rachel Opitz, hosted a virtual workshop February 16-19, 2021 via Zoom. Before the Workshop, participants were asked to explore the dataARC toolset and learning materials. The Workshop week kicked off with a large group meeting for a formal introduction to dataARC tools, and the goals and accomplishments of the project. Participants also heard short talks from dataARC Team members on development strategies for data mapping and creating combinators (Willem Kolster), the Scope note development process (Brooke Mundy), and the investment in data contributor infrastructures (Anthony Newton).
Workshop participants then dispersed to hold one-on-one or small group sessions with a dataARC Team member for a guided tour of the tools and documentation. All participants and dataARC Guides came together at the end of the week for a large group discussion of reflections from the week’s activities. Participants also met with a dataARC Team member to provide their feedback on the project and the workshop. That information is summarized in the sections below.
Participants
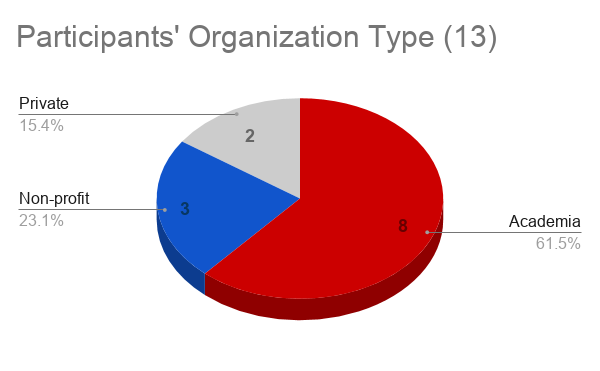
The dataARC Team invited participants from a variety of backgrounds to span many of the same scientific domains covered by the scope of the dataARC project, along with many data scientists that may not have had previous exposure to the types of data connected by the dataARC project. The summary chart shows the distribution of the types of organizations the participants represent.
The participants use a variety of types of data summarized by the list below.
- Air Quality
- Archaeological
- Archival
- Dendro Records
- Faunal
- Focus Group
- Geospatial
- Gnomic
- Historical Records
- Historical Text
- Hydrological
- Identification Of Creatures
- Interview
- Literature
- Natural Hazards
- Observations Of Creatures
- Paleoclimate
- Pollen Records
- Population Information
- Radiocarbon
- Raster
- Remote Sensing Data (Satellite And Drone)
- Spatial
- Transportation
- User Data
- Weather And Climate Data
- Zooarchaeology
These data are manipulated using a variety of analysis techniques by the participants, including:
- Processing including string manipulation, aggregation, reconstruction, rasterization
- Numerical analysis to include forming statistics, pattern detection and recognition, anomaly detection, computational model development
- Qualitative analysis includes data corroboration, construction of historical narratives,
- Data cleaning and quality control
Participants also used a wide variety of desktop and online tools in these analyses:
- Online and locally managed databases
- CSV and Excel
- Programming languages: R, Perl, Python, JavaScript
- Google Maps
- Cloud tools (AWS, Google, Azure)
- Web scraping algorithms
- Jupyter Notebooks
Conclusions and Reflections
Discussion in the final workshop session focused on possible future directions for the project and how to grow and maintain a community around the tools that currently exist. Two key takeaways of the workshop were:
- Maintaining an active community around the infrastructure is essential to its usefulness and its sustainability. The infrastructure’s design encourages its ownership by a broad community because the code and data are accessible on github and the team prioritised documentation. Multiple modes of contributing, by adding data, editing scope notes, or building use case examples emphasize community ownership. This is a different model than that used in infrastructures which aim to centralise management of data and tools.
- The conceptual model for the infrastructure and how data and concepts were linked was viewed by external participants as interesting and valuable for their own work. In many follow-up interviews participants expressed that they would have liked to be able to have a tool or infrastructure like this one to link datasets related to their own research questions, geographic regions, or completely different scientific domains. They noted that the design choice of having a single ontology in use in the dataARC infrastructure limited the topics the current infrastructure addresses. A flexible or replaceable ontology would allow them to adapt the infrastructure to address topics other than the “Changing Landscape in the North Atlantic”. A flexible ontology would also allow for the incorporation of more diverse perspectives on the concepts that are important and how they are connected to one another.
The exciting thing about a fluid ontology map is not getting towards a universal ontology, but exploring intersections and translation between them. I haven't seen anything more promising than DataARC as an approach...
-- Participant Ben Fitzhugh
What are the aims of dataARC?
While the dataARC Team has their ideas of what dataARC is, the workshop participants had some additional insight.
DataARC is aimed at providing a central ontology relating aspects of time and space focused on a particular geographical area that helps people with primarily archaeological, but also...biogeographical data. [DataARC] is seeking to relate the data in ways in which [users] can formulate queries expressed relative to that shared ontology that allows them to find matching parts of data in their corresponding datasets.
-- Antranig Basman
Data integration is the primary goal, as I see it, for transdisciplinary research, and that integration through conceptual modeling is really the innovation that dataARC is presenting, which is very cool.
-- Kitty Emery
The dataARC Infrastructure ties together datasets from different academic domains, seemingly related to archaeology.
-- Jim Foltz
It is about aggregating heterogeneous archaeological and historical data of the N. Atlantic over the early medieval to medieval periods...both conceptually and geographically.
-- Leif Isaksen
Benefits of contributing data
Discussions highlighted some of the benefits or incentives related to contributing your dataset. Many participants noted reasons to contribute data are tied to the potential for more visibility within the research community and greater public awareness of their projects. Because of the effort required to prepare, document and add data, participants noted that strong motivators and demonstrations of the added-value of contributing are needed to make researchers more likely to actively engage with an infrastructure like dataARC.
Community contributions are a fabulous idea and a great goal. I think that is the way science proceeds behind the scenes.
-- Participant Kitty Emery

Challenges of contributing data
A lack of time and resources were frequently cited as the main barriers to contributing to an infrastructure like dataARC. Secondary to this, were concerns about the data itself being underdeveloped or proprietary. Community attitudes were also noted as instrumental, as these could discourage open data practices if they were negative.
Our problem with technology is that we can't accommodate any middle ground between universal influence and no influence.
-- Participant Antranig Basman
Building Community
Many of the participants stressed that it is necessary to have a few passionate people who serve as core community members to drive the larger group forward. Those members typically act to ensure that success stories are publicized at meetings and conferences, and might work to develop outreach materials or a marketing plan for the infrastructure. The importance of maintaining all the elements of the infrastructure so that they continue to work and stay relevant to the community who uses them was also highlighted.
Places for the user community to meet and offer mutual support were highlighted as useful mechanisms for maintaining an active community. Several workshop participants suggested services like a forum or help desk to aid in fostering relationships and overcoming technical hurdles. Another strategy suggested to grow and maintain the community was the provision of dedicated dataARC resources (people, time, and/or money) to support users preparing and contributing data.
[The dataARC infrastructure and Scope Notes] help people speak the same language, which could be extremely helpful in bringing people closer together, and may provide the vocabulary needed to talk with people from other disciplines.
-- Participant Isto Huvila
Many projects involve close one-t0-one collaboration that is hard to move beyond on a community scale. DataARC is an enabler for pulling people from different domains and creating a community.
-- Participant Christine Lv
DataARC has the potential to make domain specialists see the value in particular types of data science methods and for data scientists to understand the importance of nitty gritty contextual information.
-- Andres Mejia-Ramon
Importance of an API
Users who were familiar with APIs highlighted the significant value of this part of the infrastructure. They stressed that an API provides a simple, standard interface to access dataARC data -- a key to workflow automation. Once the learning curve is overcome, it provides an additional method for retrieving query results that allow you to answer more complex questions than the Search Tool was designed to address. It’s all in how you access the data! You can write a few simple lines of code to completely automate your workflow. You can also ask more complex questions than with the Search Tool, as long as you can identify the appropriate query. In terms of productivity, in general, learning to use an API is a low cost-to-benefit ratio, enabling your research to become much more efficient.
It's really about the automation because with a well-defined API in terms of how you can access data. It just makes it easier for you to use some really simple lines of code to automate the data retrieval process instead of doing that manually, so that really allows a more streamlined kind of data analysis pipeline.
-- Participant Christine Lv